模拟器运行报错
1 | post_install do |installer| |
YYText YYTextAsyncLayer UIGraphicsBeginImageContext Deprecated #984
https://github.com/ibireme/YYText/issues/984
iOS 18适配问题记录(Xcode16正式版)
问题1:ADClient编译报错问题
报错信息

1 | Undefined symbols for architecture arm64: |
相关代码(demo)
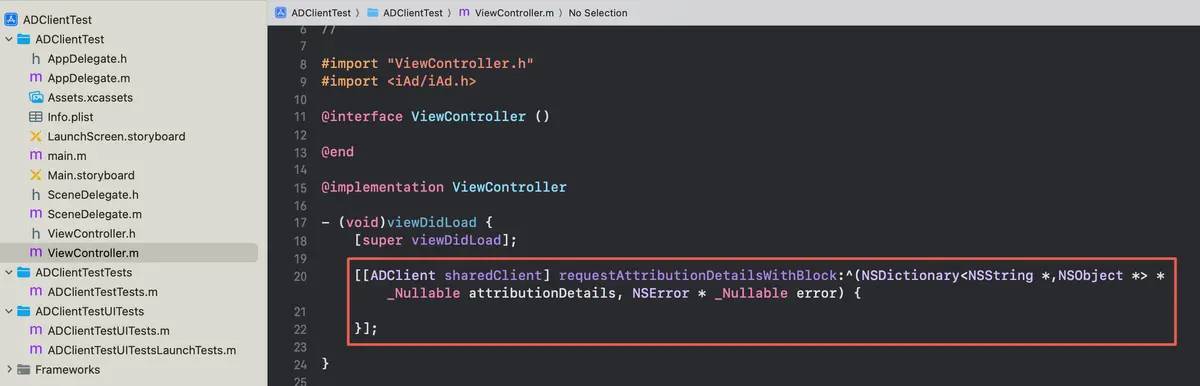
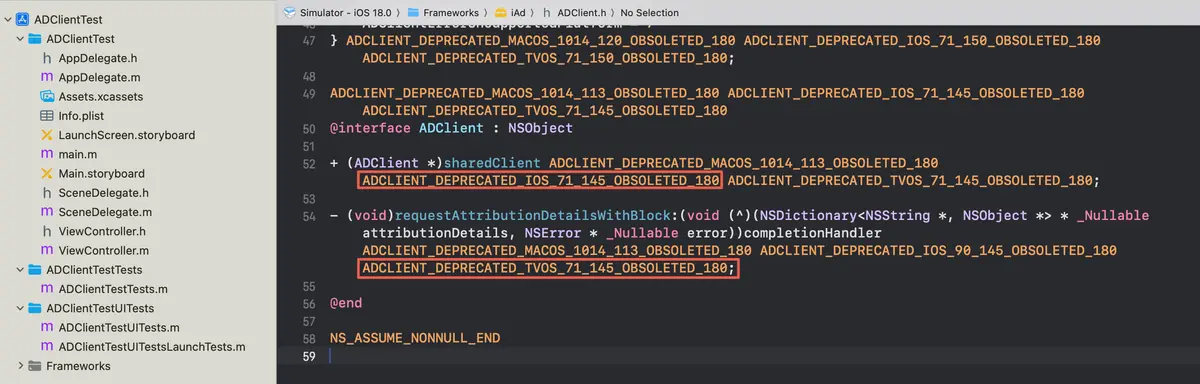
原因
苹果对AdClicent API加了一个标识
ADCLIENT_DEPRECATED_IOS_90_145_OBSOLETED_180
表示:iOS7.1-iOS14.5可用,iOS18彻底废弃,会在iOS18系统上编译失败。
解决办法
使用AdService库的AAAttribution替代,注意iOS14.3才可以使用。
代码
1 | if (@available(ios 14.3, *)) { |
参考
https://developer.apple.com/forums/thread/759156
https://developer.apple.com/documentation/iad?language=objc
问题2:Xcode16(正式版)运行时,YYCache导致crash
报错信息
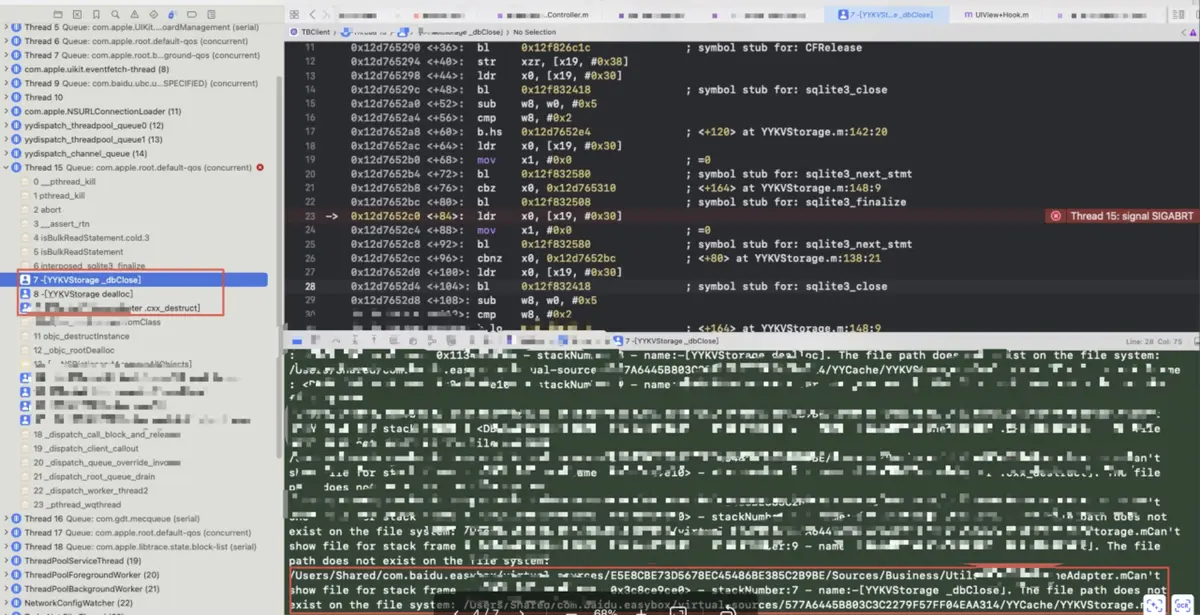
原因
在 iOS18 中,需要提前对 sqlite3_stmt 执行 sqlite3_finalize。
解决办法
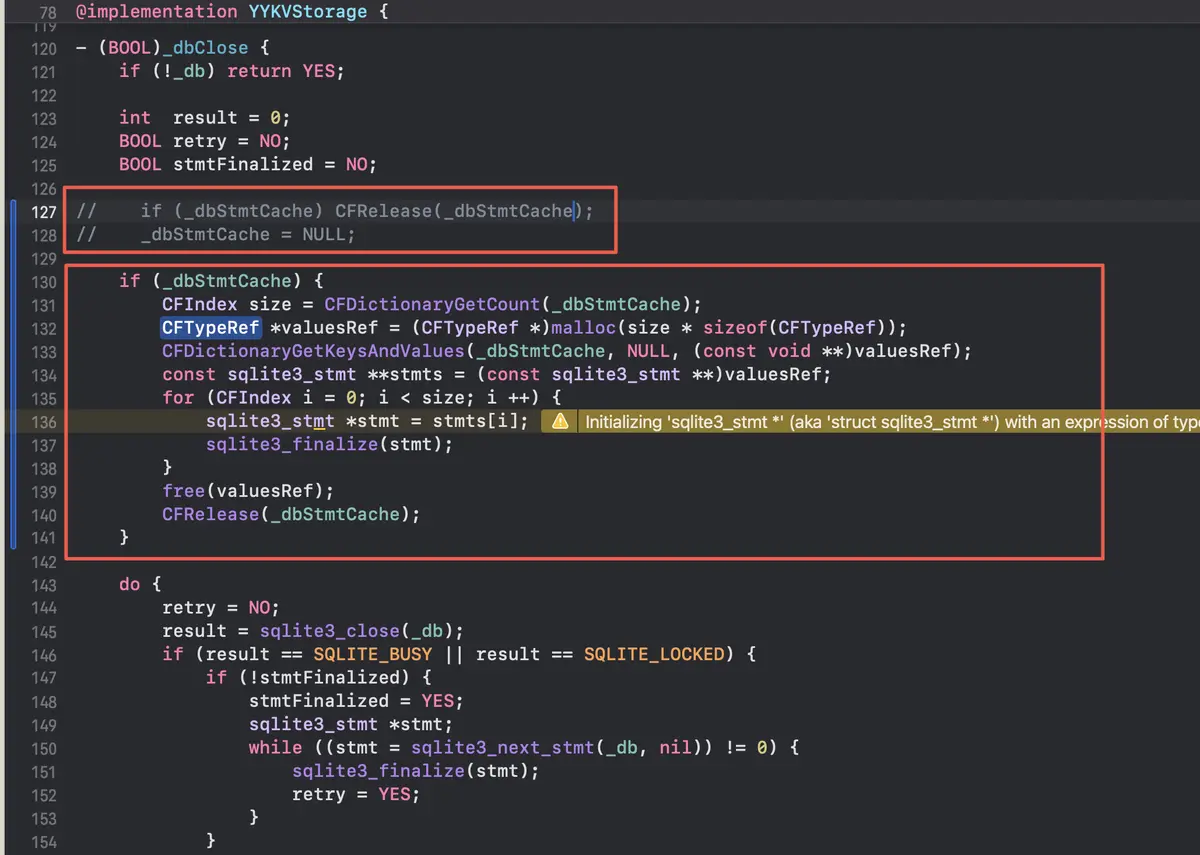
代码
1 | - (BOOL)_dbClose { |
参考
https://giters.com/ibireme/YYCache/issues/166
问题3:Xcode16正式版,addSubView crash (maskView)
报错信息
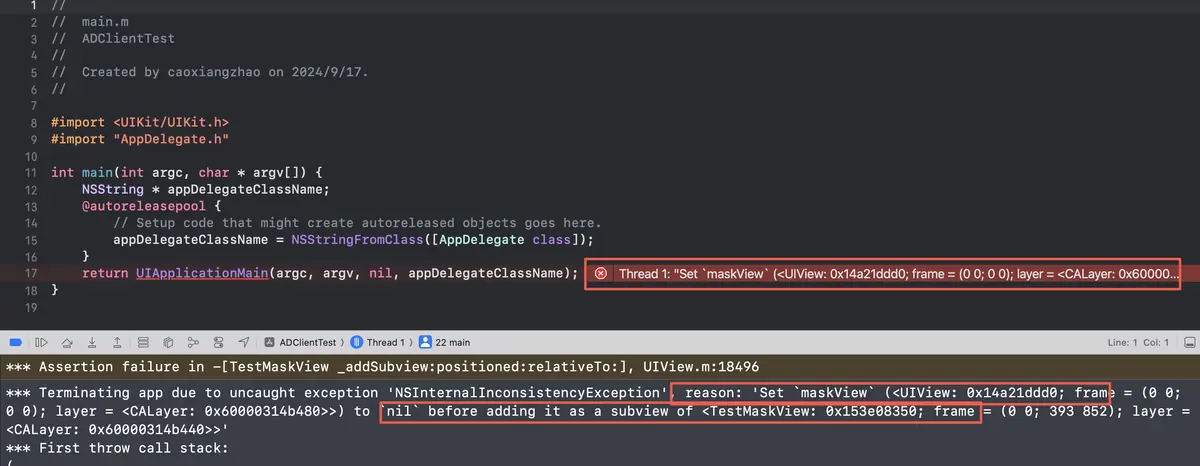
1 | *** Assertion failure in -[TestMaskView _addSubview:positioned:relativeTo:], UIView.m:18496 |
原因
iOS 18 对 UIView的maskView 增加了断言,导致如果业务代码里有同名属性可能导致触发该断言。
经测试发现:
1.自定义UIView子视图,存在同名属性maskView,会崩溃
2.自定义cell,添加到cell视图上会崩溃,添加到contentView上,则不会崩溃
3.控制器里的maskView视图属性,添加到控制器view,不会崩溃
解决办法
修改自定义视图,将自定义子组件名为maskView的视图进行重命名。